Applied Scientist - david.azcona@zalando.ie
Postdoctoral Researcher - david.azcona@dcu.ie
Fulbright Visiting scholar - david.azcona@asu.edu
Applied Scientist - david.azcona@zalando.ie
Dublin City University
Arizona State University
Educational Data Mining for Personalized Learning

Abstract
We present a new approach to automatically detecting lower-performing or “at-risk” students in computer programming modules and automatically and adaptively sending them feedback. By leveraging historical student data we built predictive models using student characteristics, prior academic history, logged interactions between students and online resources, and students’ progress in programming laboratory work. Predictions were generated every week during the semester’s classes. In addition, during the second half of the semester, students who opted-in received pseudo real-time personalised feedback. Notifications were personalised based on students’ predicted performance on the module and included a programming suggestion from a top-student in the class if any programs submitted had failed to meet the specified criteria. As a result, this helped students who corrected their programs to learn more and reduced the gap between lower and higher-performing students.
Publications
- Azcona, D., & Casey, K. (2015). Micro-analytics for Student Performance Prediction. International Journal of Computer Science and Software Engineering (IJCSSE), 4, 218–223. BibTeX / PDF
- Azcona, D., & Smeaton, A. F. (2017). Targeting At-risk Students Using Engagement and Effort Predictors in an Introductory Computer Programming Course. European Conference on Technology Enhanced Learning (EC-TEL’17), 361–366. NY, USA: Springer. BibTeX / PDF
- Azcona, D., Corrigan, O., Scanlon, P., & Smeaton, A. F. (2017). Innovative learning analytics research at a data-driven HEI. Third International Conference on Higher Education Advances (HEAd’17). Editorial Universitat Politècnica de València. BibTeX / PDF
- Azcona, D., Hsiao, I.-H., & Smeaton, A. F. (2018). PredictCS: Personalizing Programming learning by leveraging learning analytics. Companion Proceedings of the 8th International Learning Analytics & Knowledge Conference (LAK’18). ACM. BibTeX / PDF
- Azcona, D., Hsiao, I.-H., & Smeaton, A. F. (2018). Detecting Students-In-Need in Programming Classes with Multimodal Learning Analytics. Special Issue on Multimodal Learning Analytics & Personalized Support Across Spaces. Journal of User Modeling and User-Adapted Interaction. International Journal of Artificial Intelligence in Education (IjAIED). BibTeX
- More will be added soon!
Further details
A custom Virtual Learning Environment (VLE) for the teaching of computer programming has been developed at our university. This automated grading platform is currently used in a variety of programming courses across CS; including the 6+ courses we run predictions and recommendations for. Students can browse course material, submit and verify their laboratory work. This platform has been used for the past two academic years and that is the data we are using for our analysis.
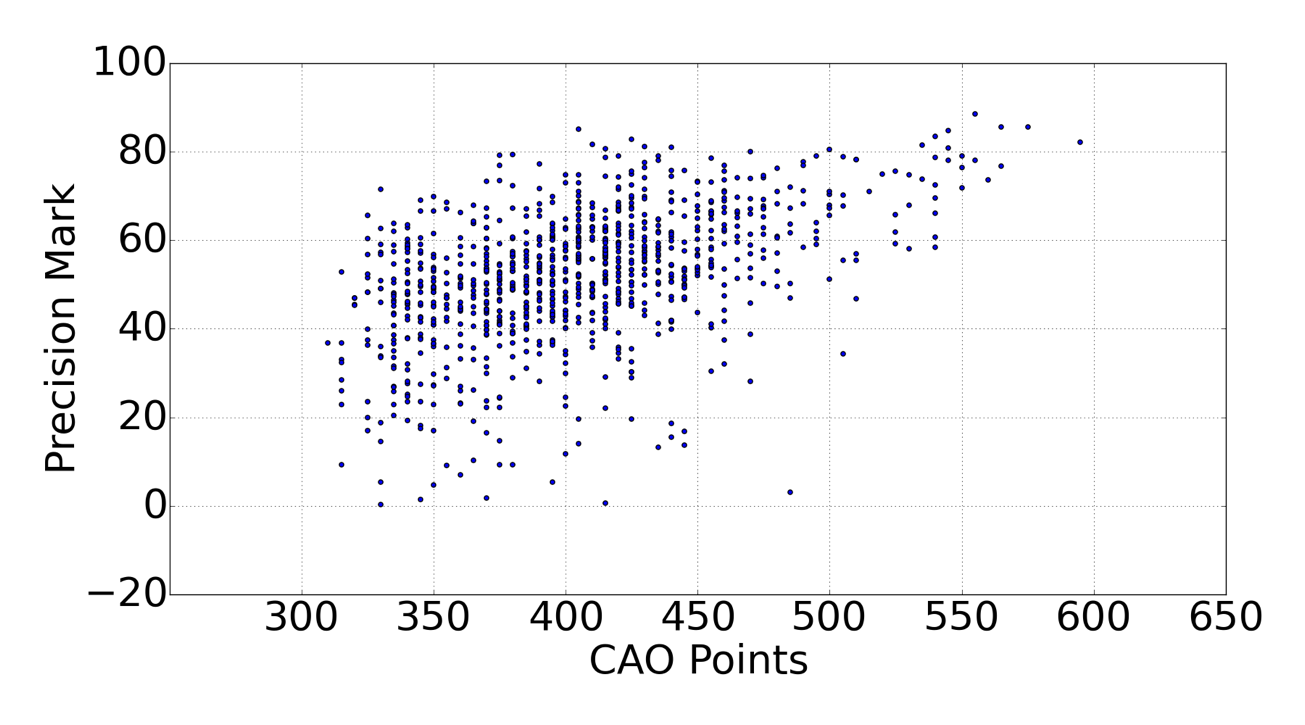
We developed predictive models, one per course, to automatically classify students’ performance. These models use the students’ digital footprints to predict their performance in computer-based laboratory programming exams. The data sources we leverage in order to model student interaction, engagement and effort in programming courses are Student Characteristics, Prior Academic history, Programming submissions, Interaction logs. The individual features extracted from these data sources are explored and correlations are measured e.g. the entry GPA points is highly correlated with how students perform in their first year at our university:
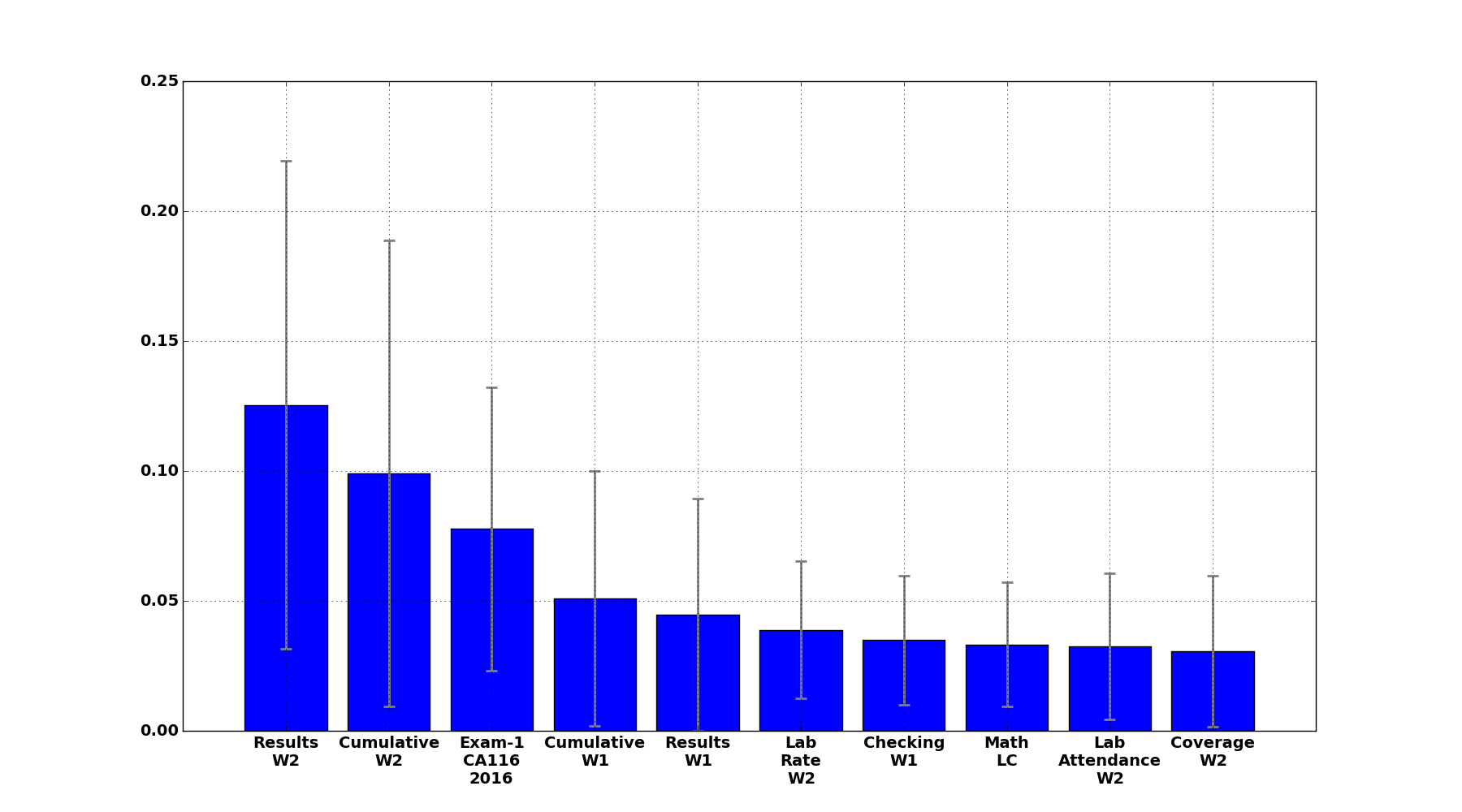
Some of the features and their importance on a given week:
More data sources can be added to our model. For instance, we also gather when students connect to the WiFi routers. This allows us to extract other kind of features such as who they spend their time with and how that affects their engagment and performance. See the following heat map:
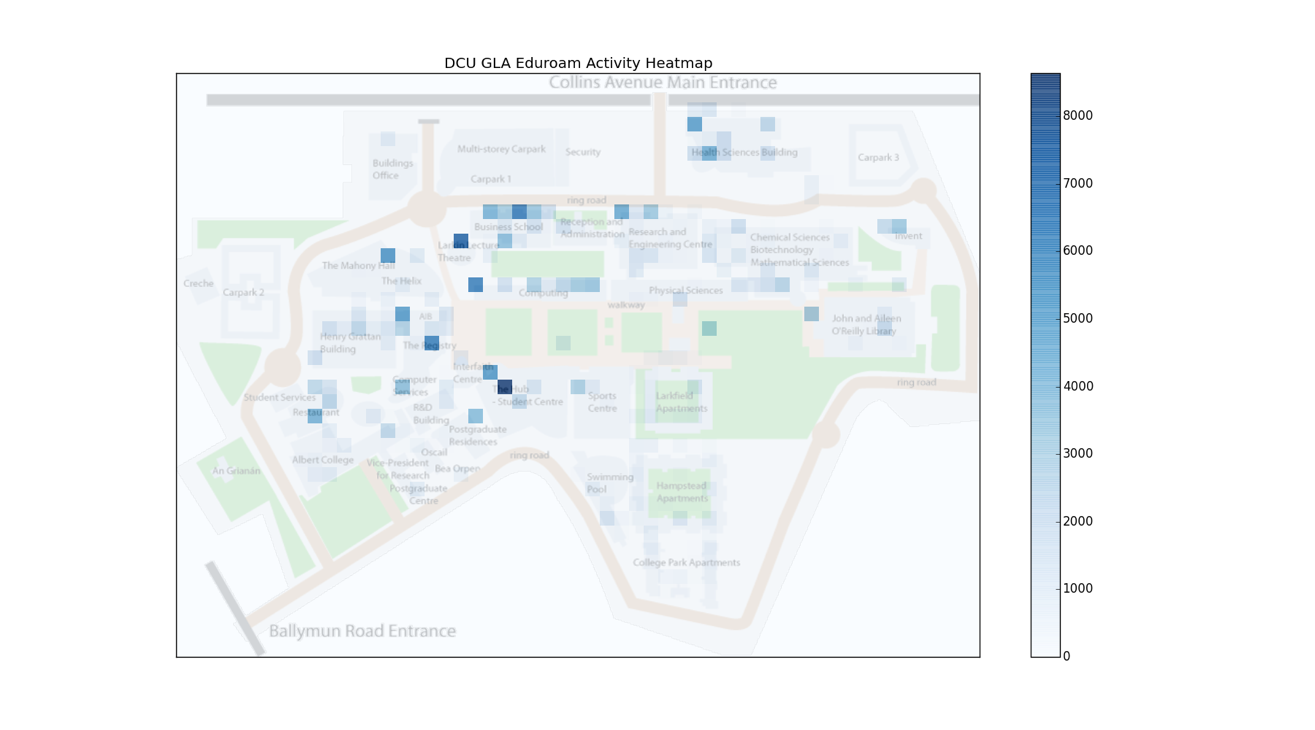
Students in some of these courses were sent weekly notifications regarding their performance and code solutions from top-students in the class. These programming suggestions were only added if the student had submitted a program that failed any of the testcases and had been considered incorrect. We developed a knowledge graph and based on the concepts the lecturer considered more important every week, we started suggesting programs for those holes.
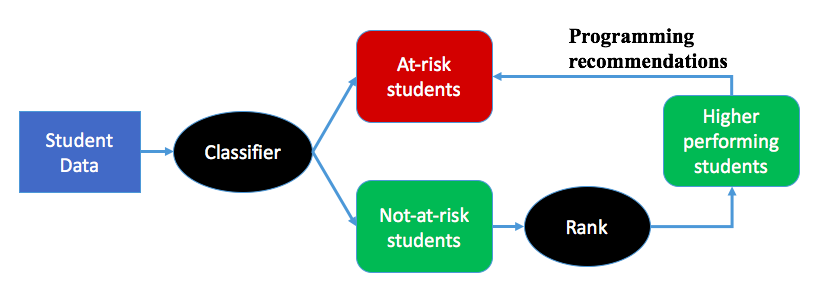
A differential improvement for students that corrected their failed programs was seen on their second laboratory exam with respect to their first assessment. It seems beneficial to the student’s learning to learn from the programs that are offered to them as advice for failed submissions.
Further details will be posted here shortly if this is something the community is interested in.
Software
The code is will be available on my Github soon.
Back to projects